Document Transformers?
Published on 27 Oct 2023 | Categories: AI
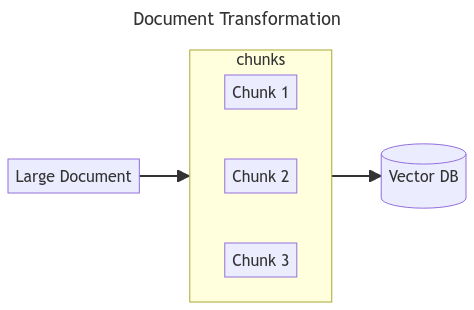
In this article we are going to discuss about the document transformers. Basically document transformer is the process in which we split the large documents into multiple smaller chunks so that they can be stored and retrieved easily from the vector database.
The document transformation seems easy but it becomes complex when you go deeper.
In RAG (Retrieval-Augmented Generation), Knowledge of LLM is extended by providing context of the document. This makes the answer of LLM more reliable and avoids hallucination. The pipeline for converting raw data looks like this in RAG:
1. Loading
2. Splitting
3. Storage
4. Retrieval
5. Generation

Document Splitting
Document splitting is process of transforming document into smaller pieces so that later on it can be passed as context in prompt. During process of splitting document we try to keep the semantically related document pieces together. We make sure every chunk has meaning ful information after splitting it from long document.
Recursive Character Text Splitter
It is very basic text splitter. It takes the list of character and tries to create chunks based on splitting on the first character, but if chunks are too large and exceed the chunk size then it takes the next character from the list and repeats the process. chunk_overlap ensures continuity between the multiple chunks.
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 100, chunk_overlap=20,separators=["\n\n", "\n", " ", ""])
This text splitter is not context splitter which means some of the chunks would be meaning less.
Split by tokenizer
In this technique we use tokenizer like spacy, tiktoken to make the chunks. This technique maintains context of chunks. SpacyTextSplitter takes two argument separator and chunk_size. Spacy splitter splits the document based on separator then it combines chunks until the chunk size limit is reached.
text_splitter = SpacyTextSplitter(separators="\n",chunk_size=1000)